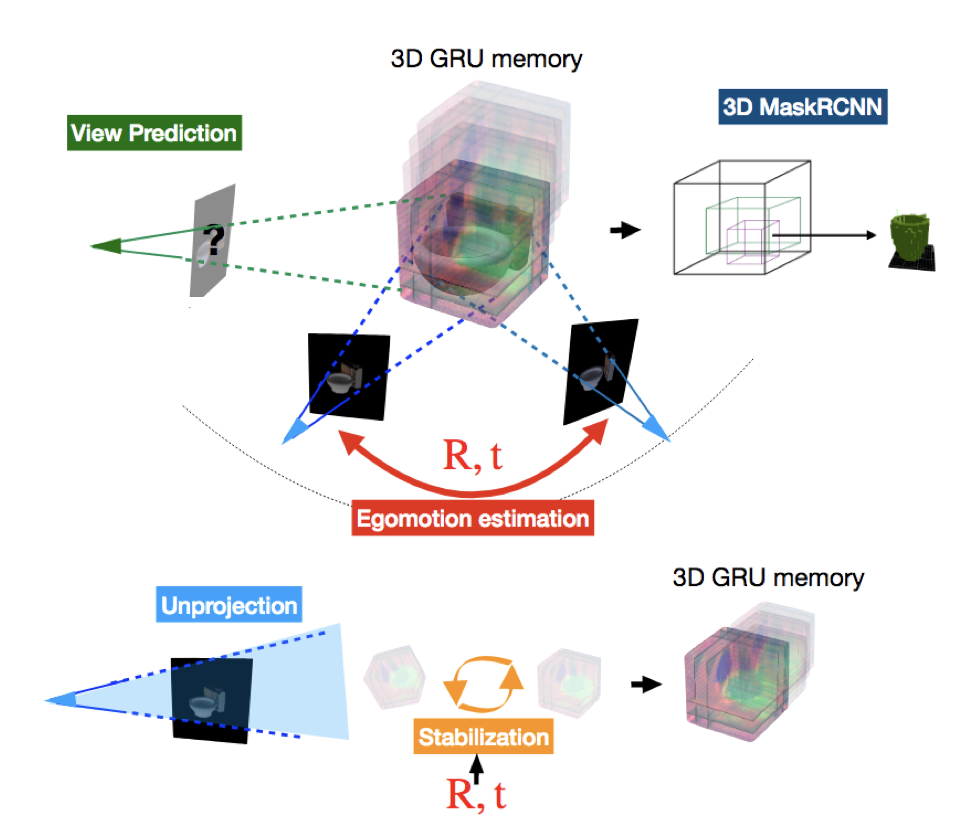
We marry two powerful ideas, geometry and deep visual representation learning, into recurrent network architectures for mobile visual scene understanding. The proposed networks learn to “lift” 2D visual features into latent 3D feature maps of the scene using egomotion-stabilized convolutions. They are equipped with differentiable geometric operations, such as, projection, unprojection, egomotion estimation and stabilization in order to compute a geometrically-consistent mapping between the world scene and their 3D latent feature space. We train the proposed architectures to predict novel image views given short frame sequences as input. Their view predictions strongly generalize to scenes with novel number of objects, appearances and configurations, greatly outperforming geometry-unaware alternatives. We train the proposed architectures to detect objects from the latent 3D feature map —as opposed to any 2D input visual frames. Resulting detections are robust to cross-object occlusions and changes of the viewpoint, and are permanent, they continue to exist even when the object leaves the field of view in the corresponding frame. We show empirically that the proposed 3D arrangement of the latent space and egomotion-stabilized latent map updates are essential architectural choices for spatial common sense to emerge in artificial embodied visual agents.
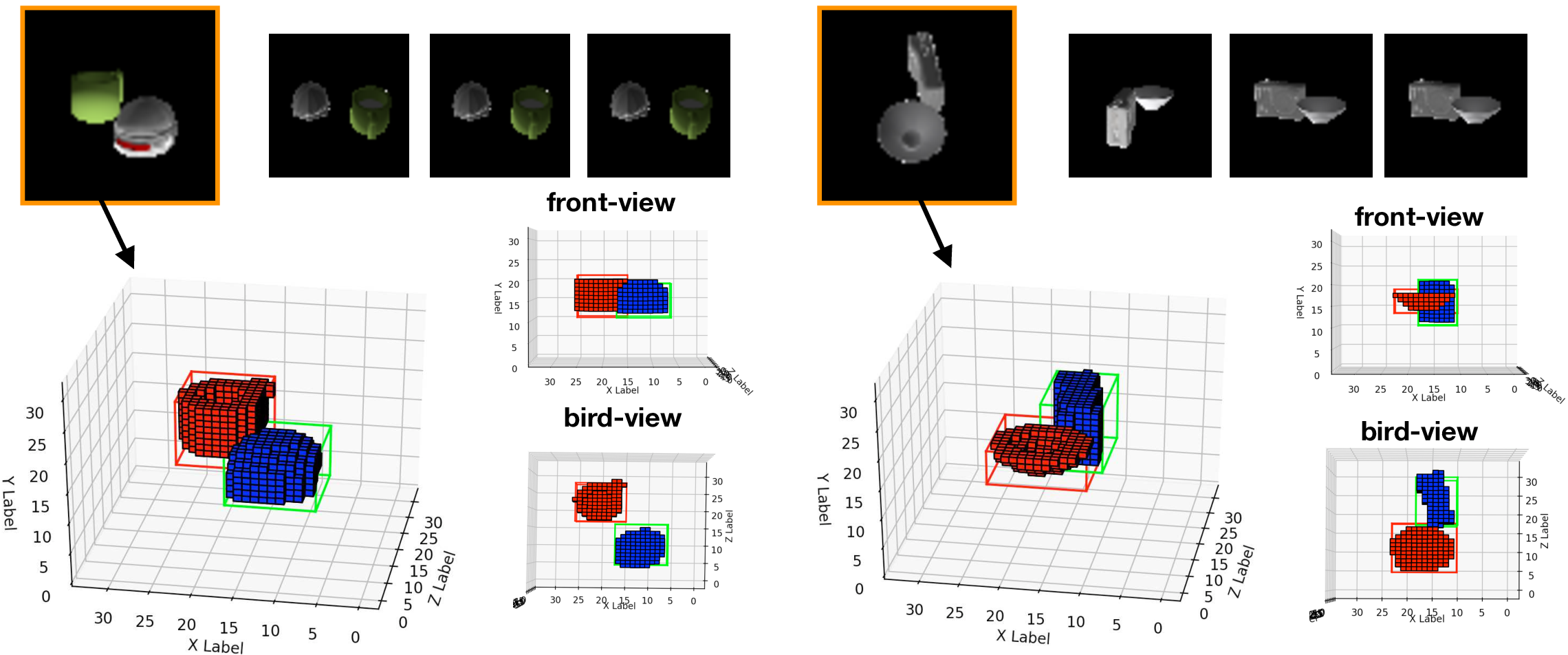
Below: Three input views and the corresponding object detections produced after each view is used to update the feature memory.




|
Hsiao-Yu Fish Tung*, Ricson Cheng*, Katerina Fragkiadaki |
We would like to thank Xian Zhou for his help on training and testing the 3D MaskRCNN. This work is partly funded by a Google faculty award.